
안녕하세요. 달소입니다.
오늘은 아주아주 유명하지만 사실 접하기 쉽지않은 오픈소스 분산 빅데이터처리 프레임워크인 하둡을 설치하는 방법입니다.
하둡이 익숙치 않은분들이라도 빅데이터라는 이름은 많이 들어보셨을텐데요.
하둡은 이러한 빅데이터 분석을 도와주는 오픈소스 프로젝트로 2006년에 공개되었습니다.
하둡에 관한 많은 정보들이 있지만 장단점에 대해서는 아래 글을 참고하시는게 좋을듯합니다.
여기서는 Ubuntu 22환경에서 하둡을 싱글노드로 직접 구축해보았습니다.
자바설치
하둡은 자바를 기반으로 동작하는 프레임워크이기때문에 자바설치부터 진행합니다.
apt update

apt install openjdk-8-jdk -y
설치가 완료되면 버전을 확인해줍니다.
java -version; javac -version

하둡 계정 생성하기
보안 강화 및 클러스터 관리 용으로 별도의 하둡계정을 만들어줍니다.
adduser hadoop
su – hadoop으로 계정전환을 해주시고
pw없이 접근할 수 있도록 키 생성 후 저장해주겠습니다.
ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
이제 본격적인 하둡설치를 진행합니다.
공식홈페이지에서 최신버전으로 다운로드
2023/01/31 기준 3.3.4
hadoop계정의 홈폴더에서 진행해주세요.
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
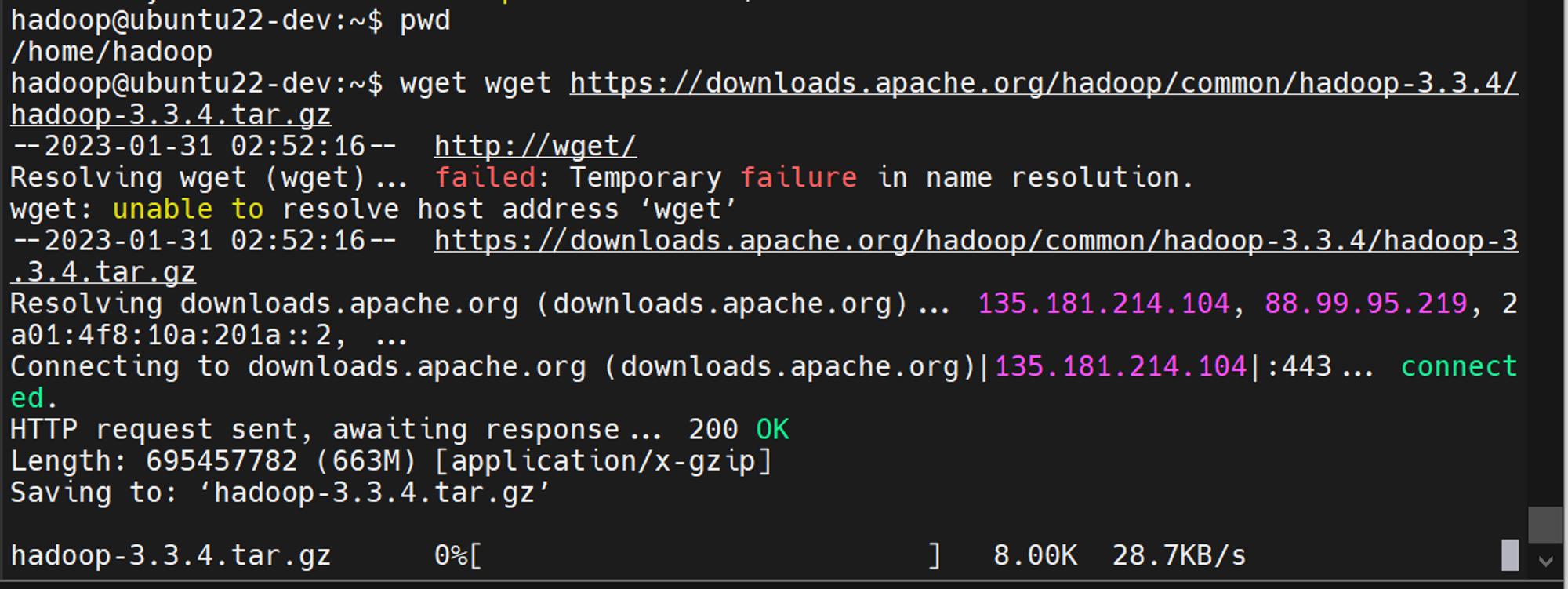

용량이 꽤되네요.
압축도 풀어줍니다.
tar xzf hadoop-3.3.4.tar.gz
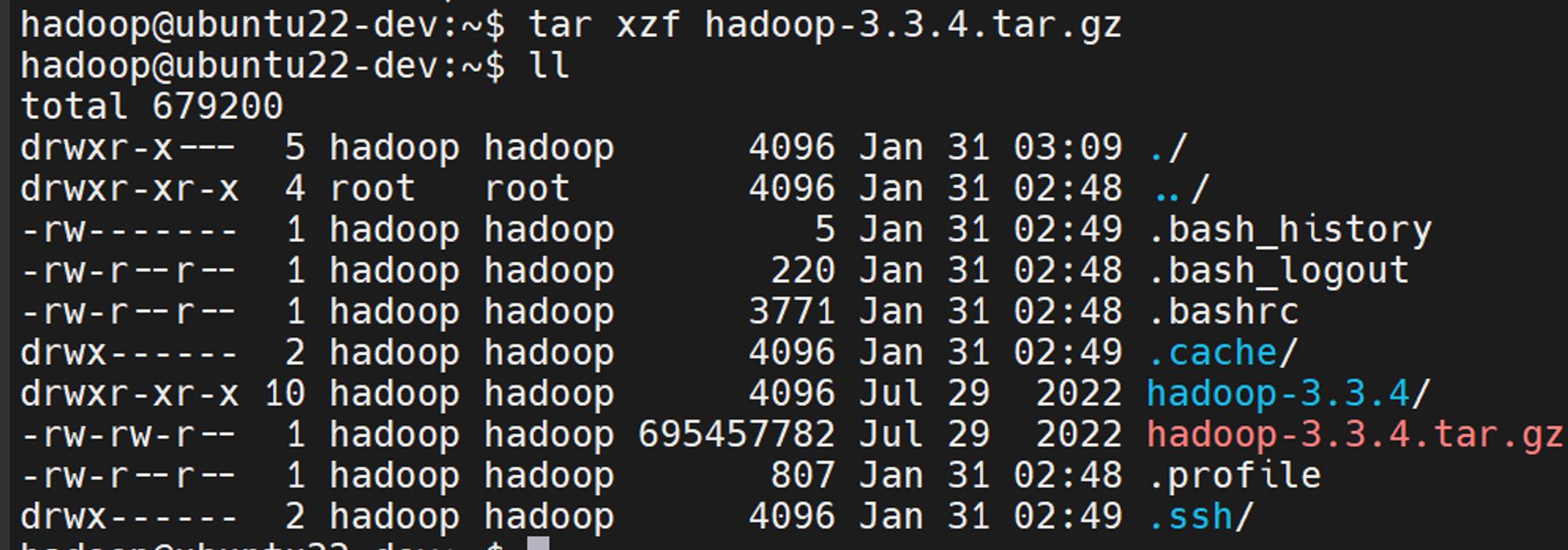
압축해제가 되었으면 설치를 진행하겠습니다.
설치는 vm이기때문에 단일노드로 설치하는 pseudo-distributed mode로 설치하겠습니다.
(단일 자바 프로세스로 운영)
설정값을 수정할 파일 목록은 아래와 같습니다.
- bashrc
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site-xml
- yarn-site.xml
bashrc 환경변수 설정하기.(hadoop 계정으로 진행)
vi ~/.bashrc
최하단으로 내려가서 아래 내용 추가.
#Hadoop Related Options export HADOOP_HOME=/home/hadoop/hadoop-3.3.4 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
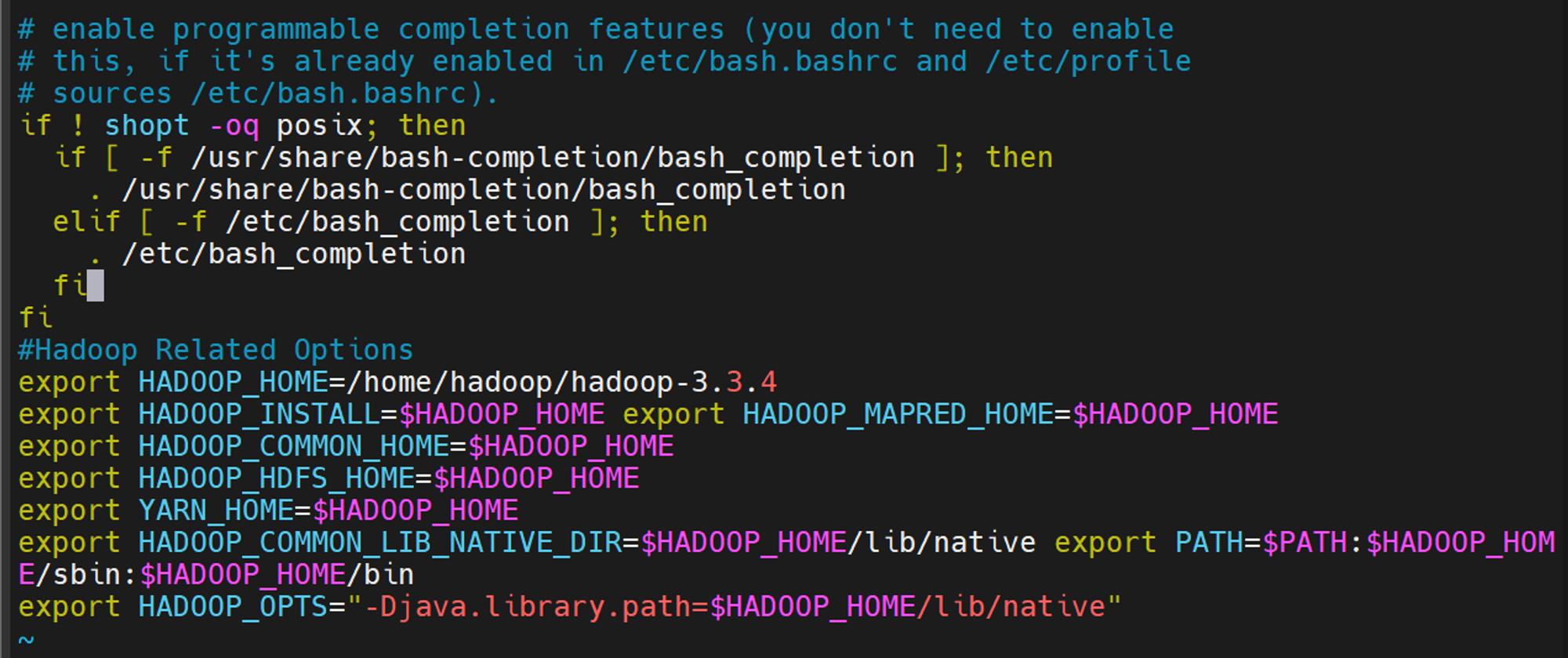
source ~/.bashrc 후 echo $HADOOP_HOME 을 쳤을때 아래처럼 나오면 성공입니다.

hadoop-env.sh 수정하기.
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
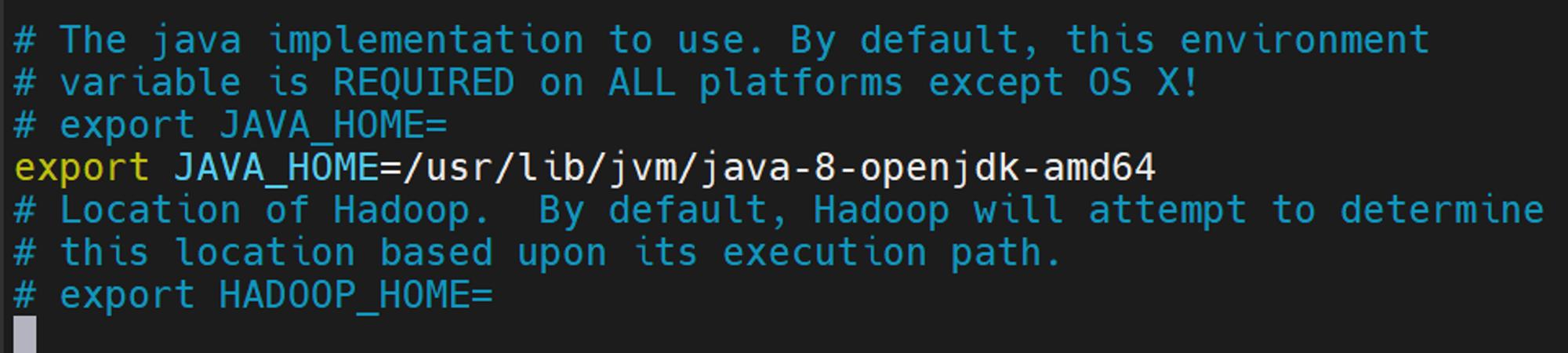
export JAVA_HOME= 밑에 아래내용을 추가해주세요.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
core-site.xml 수정하기.
core-site./xml은 HDFS와 핵심 Property들을 정의하는 파일입니다.
여기서는 tmp dir경로와 hdfs의 주소값을 정의해줍니다.
값 수정전에 tmp폴더를 만들어주세요,.

vi $HADOOP_HOME/etc/hadoop/core-site.xml
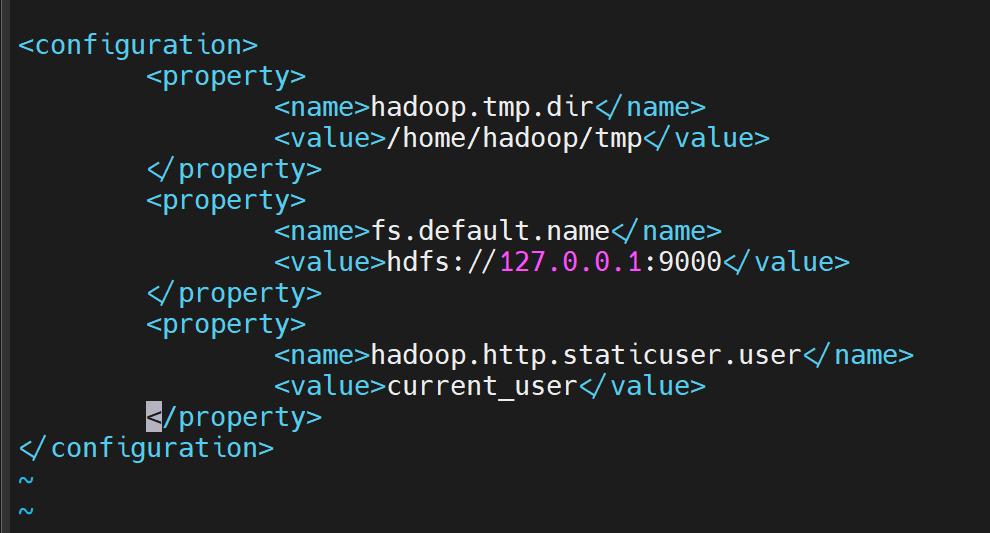
최하단 <configuration> 사이에 아래 내용을 복붙해주세요.
<property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://127.0.0.1:9000</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property>
hdfs-site.xml 수정하기.
이 파일은 데이터 노드와 네임노드의 저장소 디렉터리 설정값을 수정해줍니다.
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
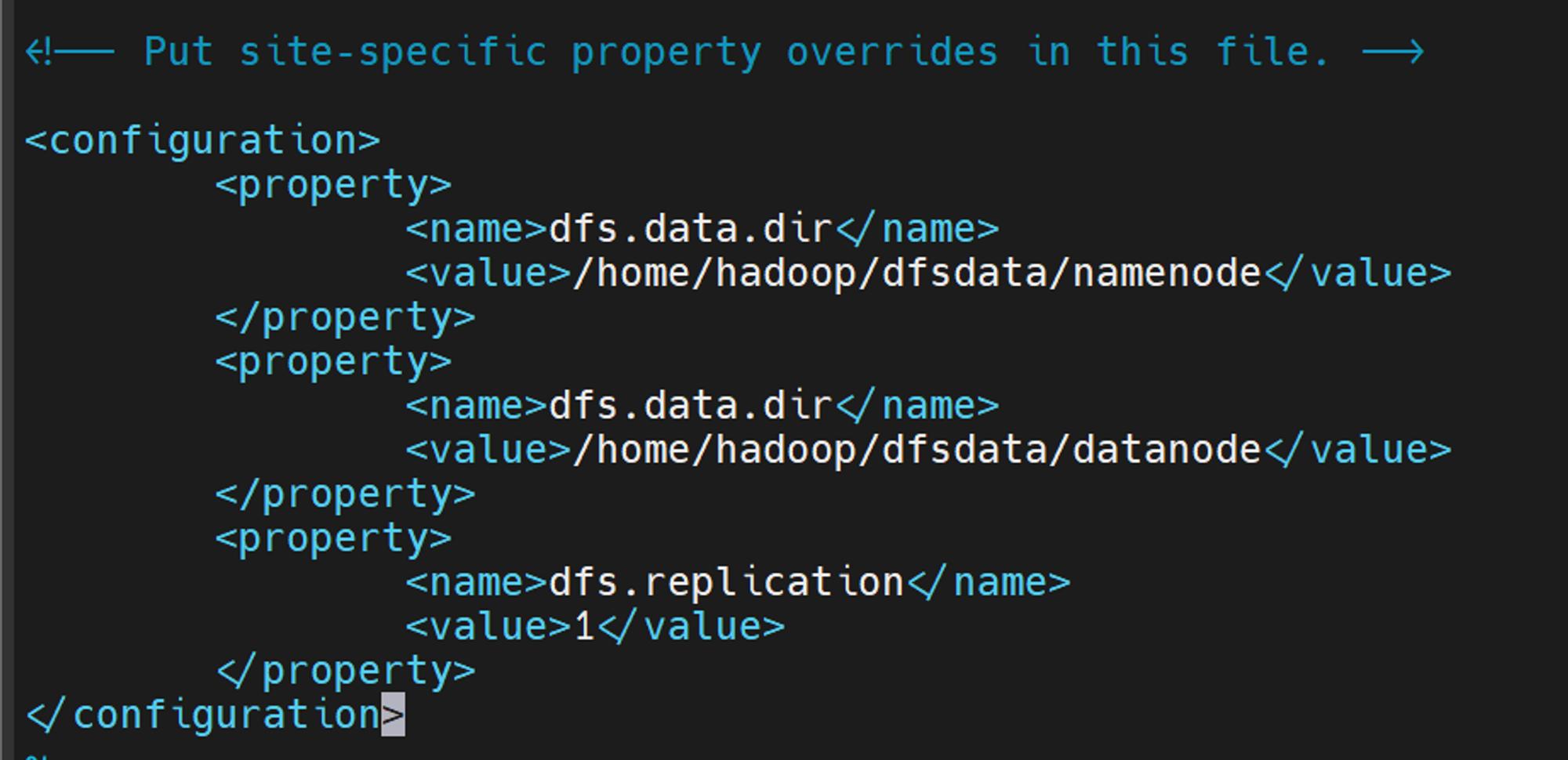
마찬가지로 configuration 안에 property를 넣어주시면됩니다.
<property> <name>dfs.data.dir</name> <value>/home/hadoop/dfsdata/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>/home/hadoop/dfsdata/datanode</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>
mapreduce 정의를 위한 mapred-site.xml파일을 수정
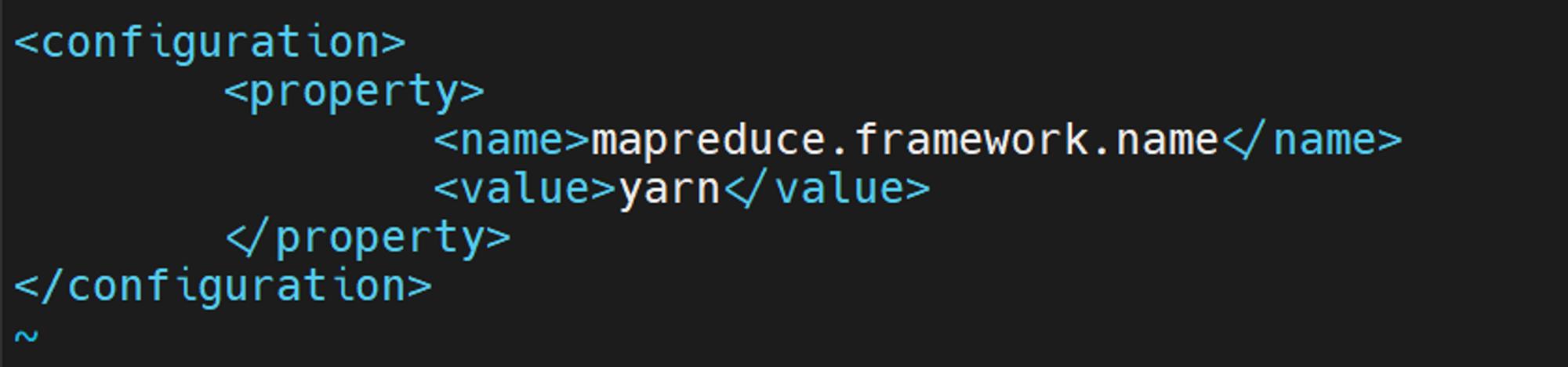
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
yarn 셋팅을 위한 yarn-site. xml을 수정
여기서 node manager, Resource manager, containers, application master설정을 진행합니다.
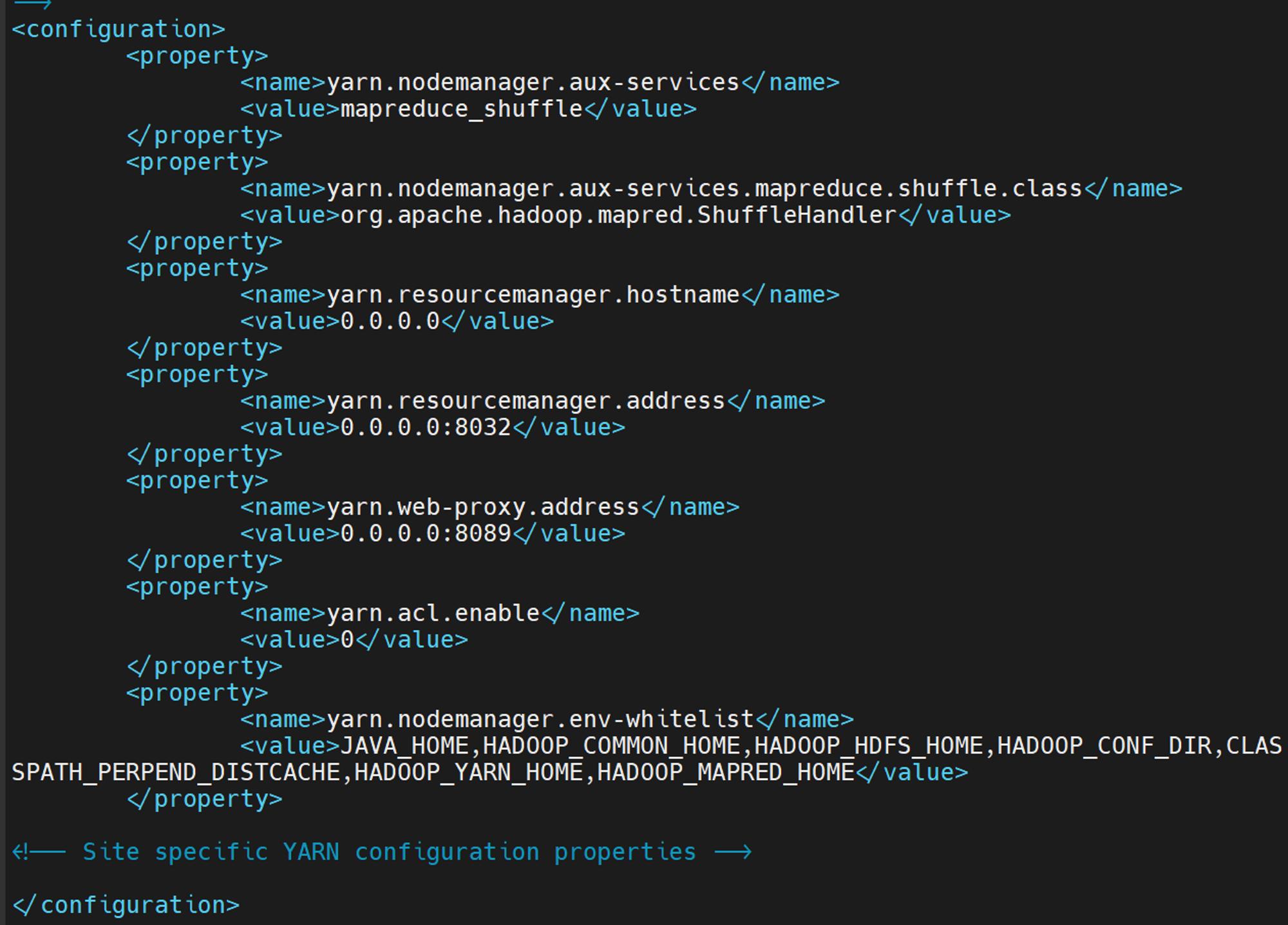
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>0.0.0.0</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>0.0.0.0:8032</value> </property> <property> <name>yarn.web-proxy.address</name> <value>0.0.0.0:8089</value> </property> <property> <name>yarn.acl.enable</name> <value>0</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property>
HDFS Namenode 초기화.
처음으로 하둡 서비스를 시작하기전에 네임노드를 초기화시켜줘야합니다.
hdfs namenode -format
모두 완료되면 하둡 클러스터를 시작해줍니다.
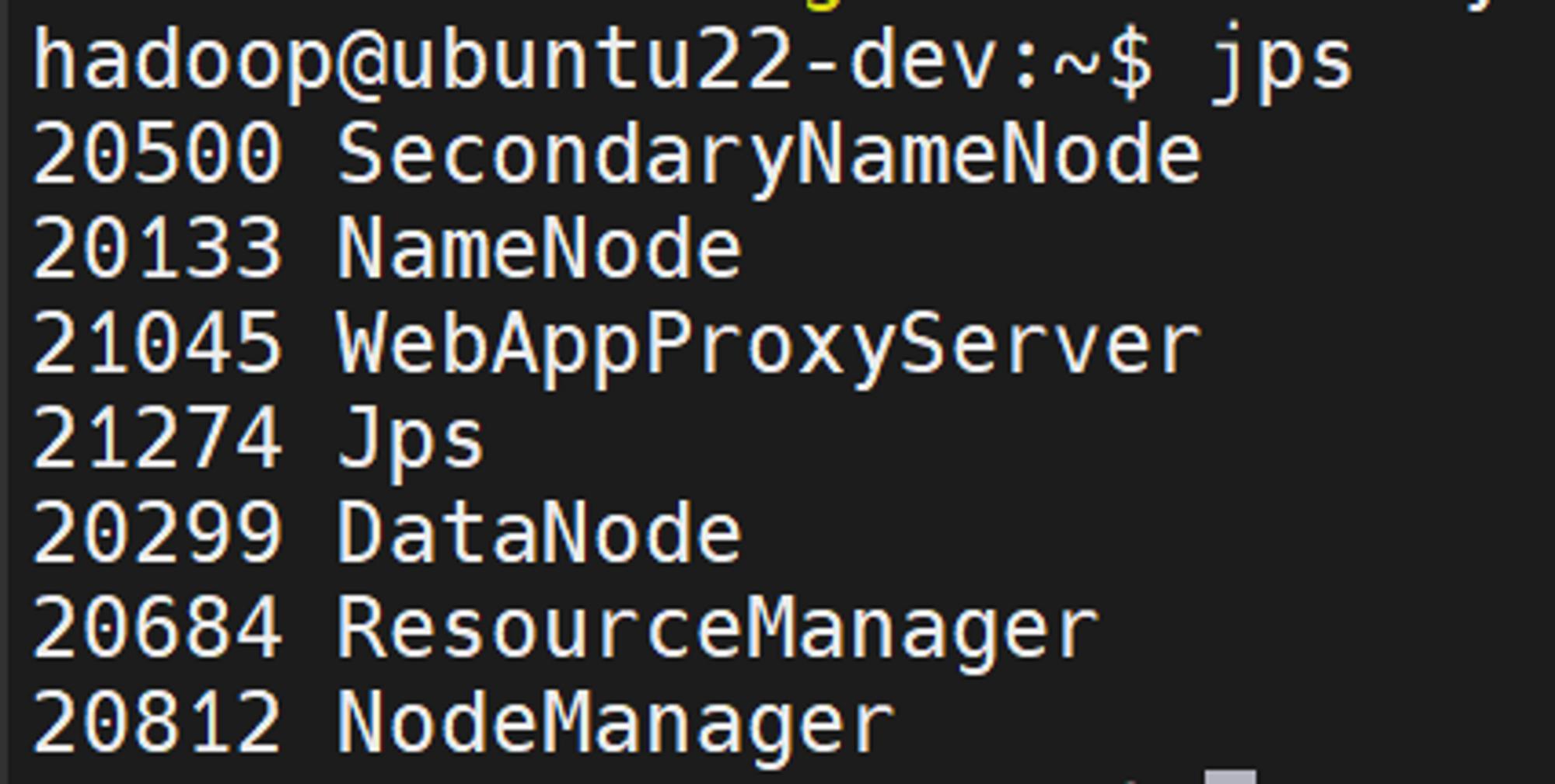
hadoop-3.3.4/sbin/start-all.sh
jps로 프로세스 확인이 가능합니다.
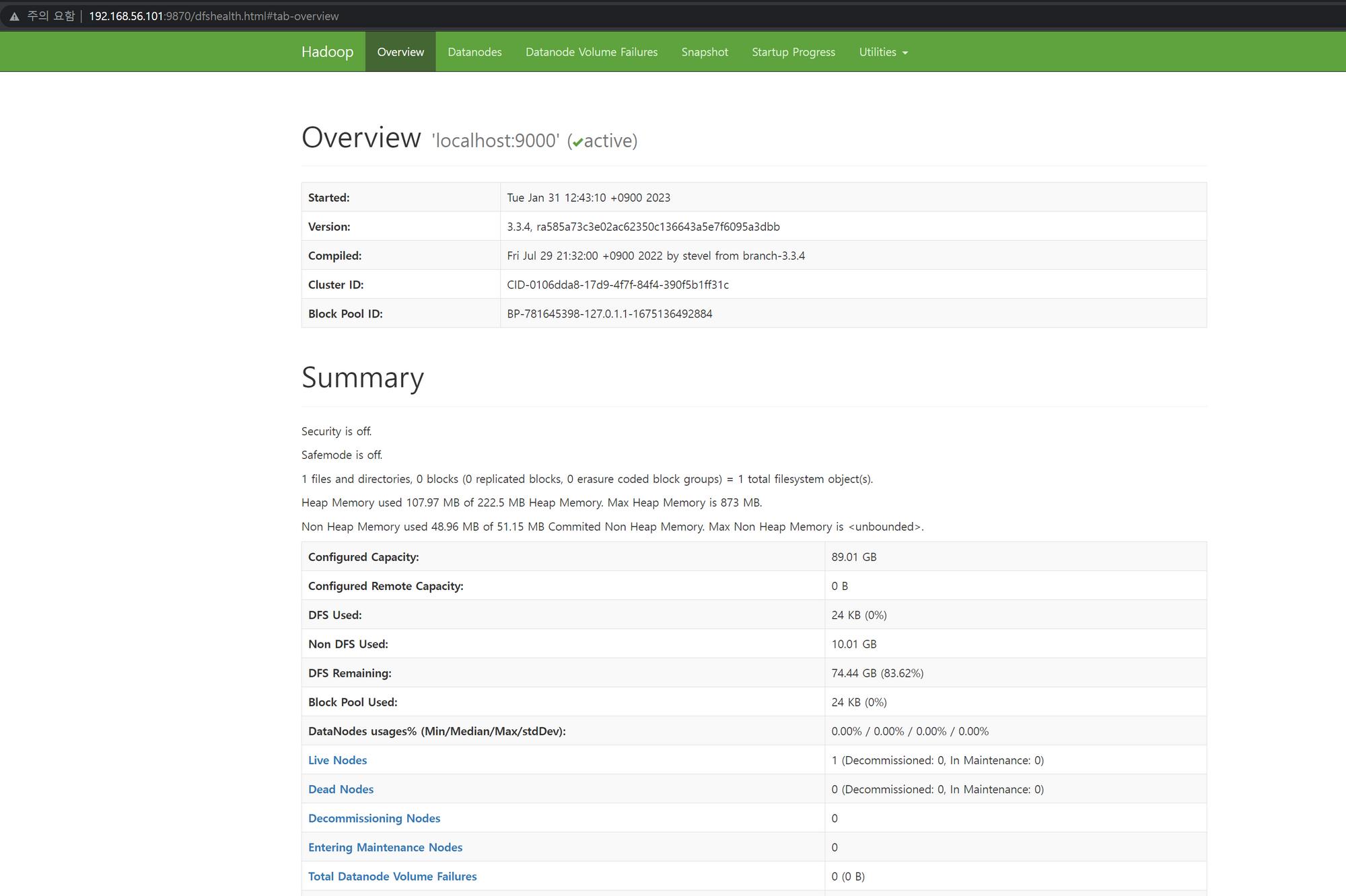
이제 웹으로 Hadoop WEB UI에 접속해줍니다.
http://ip:9870 입니다.
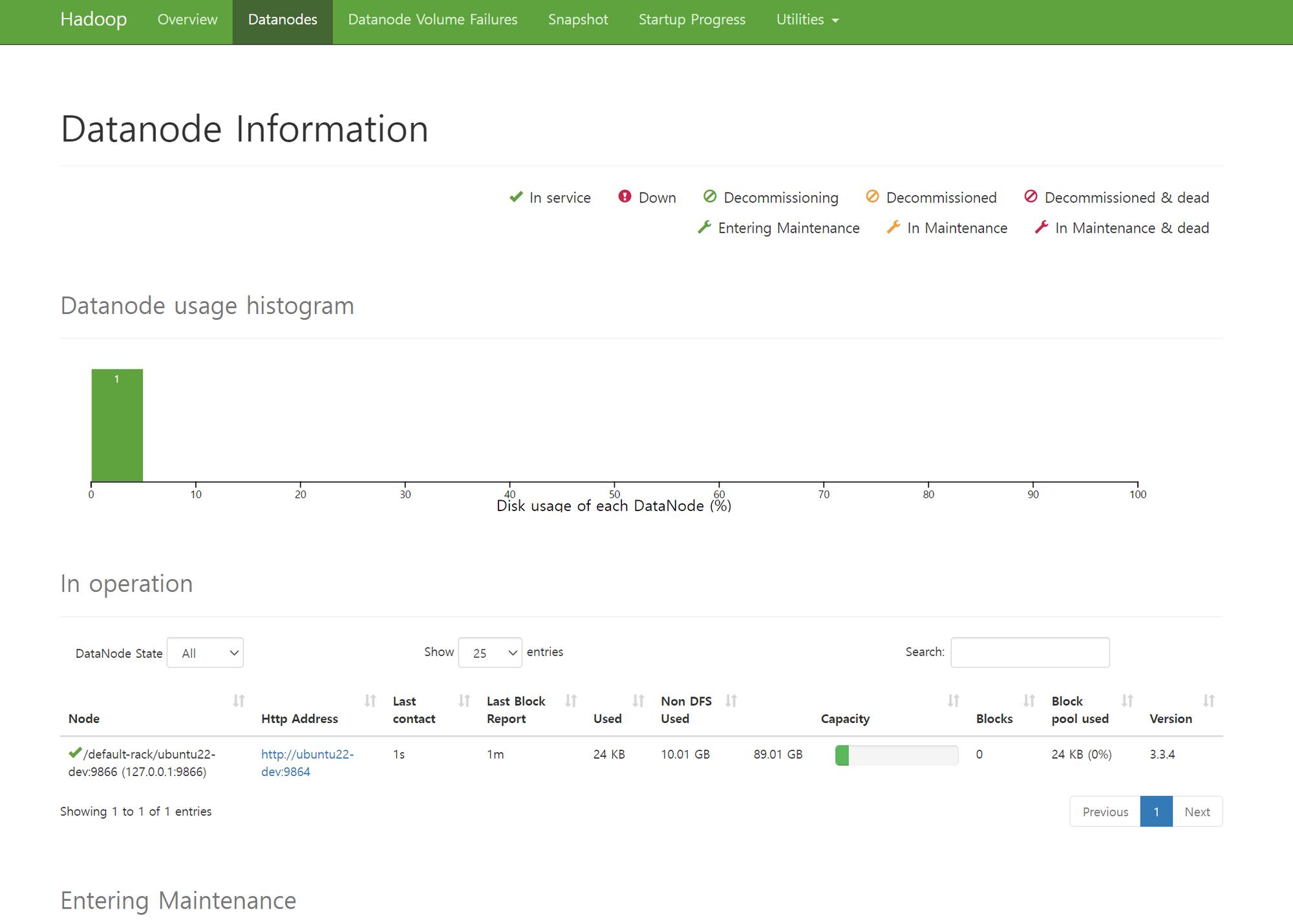
데이터노드
브라우저 파일시스템도있네요 ㄷ
http://IP:8042/node
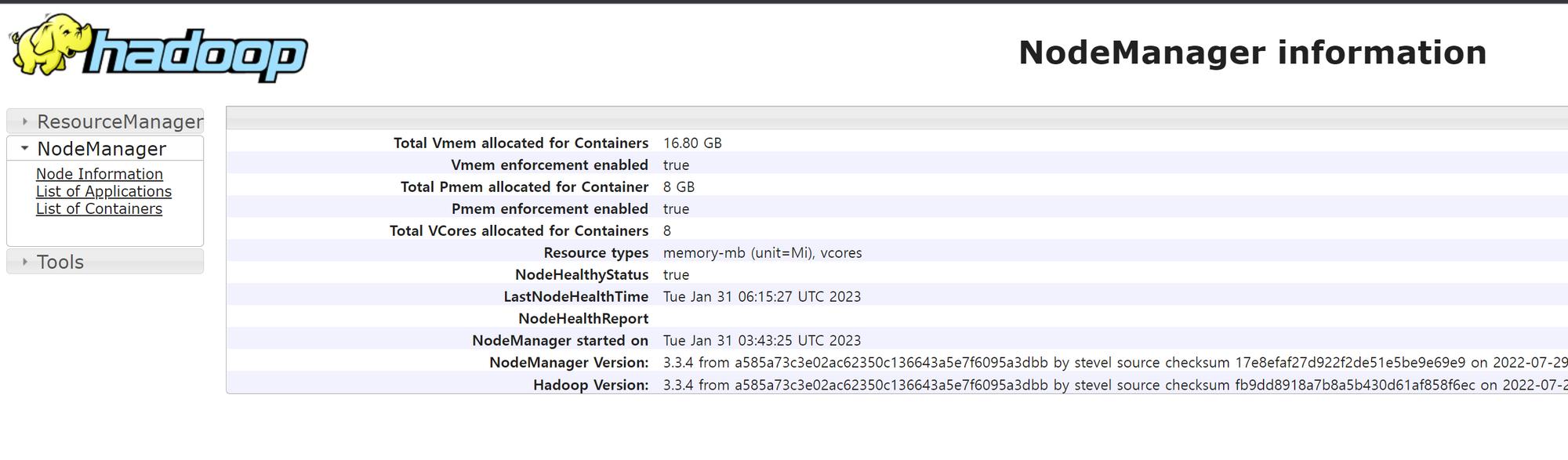
http://IP:8088/cluster
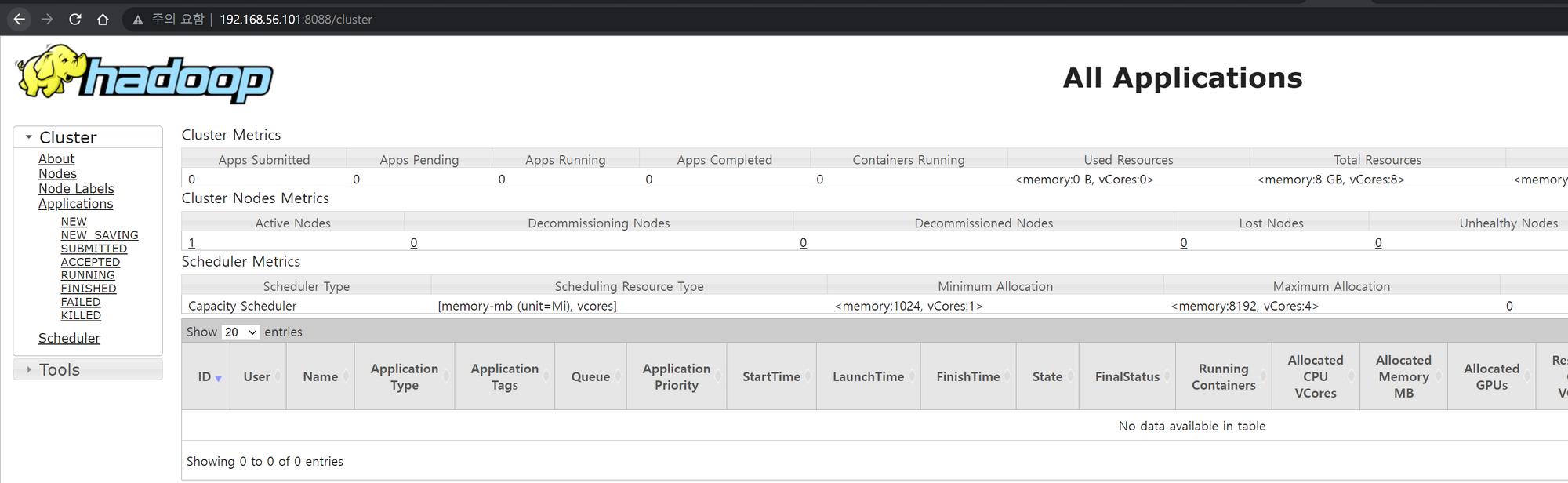
뭐,,, 복잡하긴한데 꽤나 재미있었습니다
쓸일이 있을까싶긴하지만요..하하..